Πόση προκατάληψη υπάρχει στη λογοτεχνία απέναντι σε γυναίκες και άνδρες;

Η ερευνήτρια του Πανεπιστημίου της Κοπεγχάγης Isabelle Augenstein μαζί με τους συνεργάτες της ερεύνησαν 3,5 εκατομμύρια λογοτεχνικά και μη βιβλία, τα οποία έχουν εκδοθεί στην Αγγλία, μεταξύ 1900 και 2008, σε μια προσπάθεια να βρουν αν υπάρχει διαφορά μεταξύ των τύπων των λέξεων που χρησιμοποιούνται για να περιγράψουν τους άνδρες και τις γυναίκες στη λογοτεχνία.
«Μπορούμε ξεκάθαρα να δούμε ότι οι λέξεις που χρησιμοποιούνται για τις γυναίκες αναφέρονται περισσότερο στο παρουσιαστικό τους, από ό,τι οι λέξεις που χρησιμοποιούνται για να περιγράψουν τους άντρες» είπε η Dr. Augenstein.
«Έτσι μπορέσαμε να επιβεβαιώσουμε μια ευρεία αντίληψη, μόνο που τώρα το κάνουμε σε ένα στατιστικό επίπεδο».
Χρησιμοποιώντας ένα ηλεκτρονικό μοντέλο, η Dr. Augenstein και οι συν-συγγραφείς από τα University College London, Johns Hopkins University, Microsoft Research και University of Cambridge ανέλυσαν ένα σύνολο 3,5 εκατομμυρίων βιβλίων.
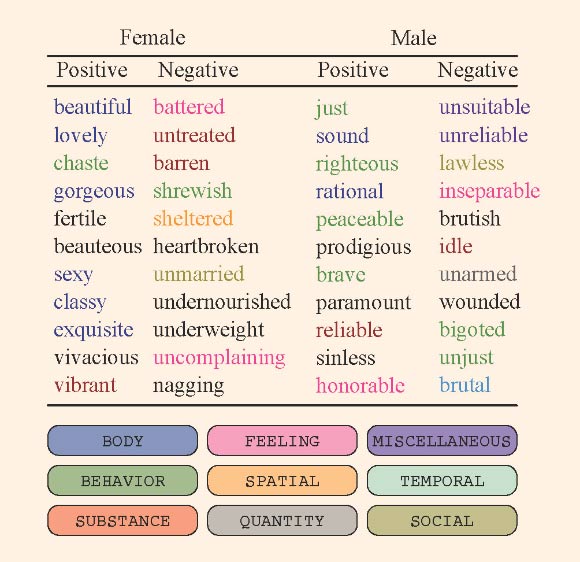
Οι επιστήμονες αφαίρεσαν επίθετα και ρήματα που συνδέονται με ουσιαστικά που αφορούν φύλο (π.χ., «κόρη», «αεροσυνοδός»). Για παράδειγμα, σε συνδυασμούς όπως «σέξι αεροσυνοδός».
Στη συνέχεια ανέλυσαν αν οι λέξεις είχαν ένα θετικό, αρνητικό ή ουδέτερο συναίσθημα και, κατόπιν, τις κατηγορίες στις οποίες οι λέξεις θα μπορούσαν να διαιρεθούν.
«Οι αναλύσεις μας καταδεικνύουν ότι αρνητικά ρήματα που συνδέονται με το σώμα και την εμφάνιση χρησιμοποιούνται πέντε φορές περισσότερο στις γυναίκες από ό,τι στους άνδρες», είπαν.
«Οι αναλύσεις επίσης κατέδειξαν ότι θετικά και ουδέτερα επίθετα που αφορούν το σώμα και την εμφάνιση εμφανίζονται περίπου δύο φορές πιο συχνά στις περιγραφές γυναικών, ενώ οι άνδρες πιο συχνά περιγράφονται με τη χρήση επιθέτων που αφορούν τη συμπεριφορά και τις προσωπικές ποιότητές τους».
Το «όμορφη» και «σέξι» ήταν τα δύο επίθετα που πιο συχνά χρησιμοποιούνται για να περιγράψουν γυναίκες. Οι πιο συχνές λέξεις για την περιγραφή ανδρών περιλάμβαναν τα «δίκαιος», «λογικός» και «γενναίος».
«Αν και πολλά από τα βιβλία εκδόθηκαν αρκετές δεκαετίες πριν, συνεχίζουν να παίζουν έναν ενεργό ρόλο», είπε η Dr. Augenstein.
«Καθώς η τεχνητή νοημοσύνη και η γλωσσική τεχνολογία όλο και περισσότερο επικρατούν στην κοινωνία, είναι σημαντικό να γνωρίζουμε τη γλώσσα που χρησιμοποιείται για τα φύλα», πρόσθεσε.
«Μπορούμε να προσπαθήσουμε να το λάβουμε αυτό υπόψη όταν διαμορφώνουμε μοντέλα μηχανών που μαθαίνουν, χρησιμοποιώντας είτε λιγότερο μεροληπτικό κείμενο είτε αναγκάζοντας τα μοντέλα να αγνοούν ή να αντιδρούν στις μεροληψίες. Και τα τρία αυτά είναι πιθανά».
Τα αποτελέσματά τους οι ερευνητές τα παρουσίασαν στις 29 Ιουλίου στο 2019 Annual Meeting of the Association for Computational Linguistics στη Φλωρεντία.
Πηγή: Sci-news









